I manage most of my photographic output with PhotoPrism. It's wonderfully simple, I can manually (or automatically sync them in this structure from my phone, using the PhotoSync app for iOS) organize my photos in folders like so, which I've done for close to 20 years now, and have PhotoPrism provide a very nice browsing frontend for my collection:
...
2025/
07/
special_event/
2025-07-01T15:30:45-iphone5s.jpg
...
mobile/
2025-07-01T15:30:45-iphone5s.jpg
...
...
...
I've started doing it this way after getting locked into iPhoto (in 2005 or so), which had a proprietary way to organize photos which wasn't file system based and thus my photos weren't portable to other programs, as I've come to realize. I'm still using Capture One for more "serious work" (I'm an amateur though), and haven't found a good way to sync it's library with Photoprism yet.
I'm using PhotoPrism in read-only mode, completely managing the data myself. As far as I'm concerned Photoprism is just a viewer for my photos. While this works great, with now close to 80,000 photos in folders it's getting harder and harder to find specific things. So it's great that Photoprism integrates machine learning models since quite some time (as long as I've been using it, so maybe ~5 years?) to make organizing a large photo library easier.
Running photoprism vision ls in the photoprism docker container shows the following by default:
┌─────────┬─────────┬─────────┬────────────┬─────────────────────────────────────────────────────┬────────────┬──────────┐
│ Type │ Name │ Version │ Resolution │ Uri │ Tags │ Disabled │
├─────────┼─────────┼─────────┼────────────┼─────────────────────────────────────────────────────┼────────────┼──────────┤
│ labels │ NASNet │ Mobile │ 224 │ │ photoprism │ No │
│ nsfw │ Nsfw │ │ 224 │ │ serve │ No │
│ face │ FaceNet │ │ 160 │ │ serve │ No │
│ caption │ │ │ 224 │ http://photoprism-vision:5000/api/v1/vision/caption │ │ No │
└─────────┴─────────┴─────────┴────────────┴─────────────────────────────────────────────────────┴────────────┴──────────┘
So it uses a face detection model from Google, FaceNet, an image classification model for automated labelling called NASNet, and some NSFW detection model I couldn't identify. The face detection model does work quite well, although it has problems with children slowly evolving from babys to toddlers (it doesn't detect my child in newer pictures, although there's plenty of training data available). The labeling model on the other hand does odd things at times:
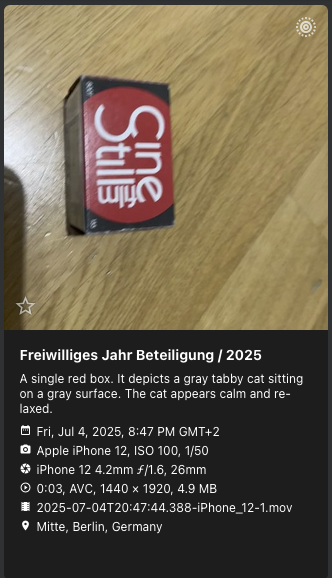
Another model, the last line in the above listing, refers to the photoprism-vision project. By default captions aren't generated, although it's listed here. Intrigued, browsing the pull requests of the repo on github I found something quite interesting, the integration of Ollama for integration of LLMs. I'm running Ollama for private LLM usage (Open WebUI and llm, the CLI, mostly) for personal stuff and at work as well. Having recently worked with the Gemma3-4B model, stumbling over it's vision capabilities I was even more intrigued what this enables me to do, and I tried to set this up.
Actually Setting Up PhotoPrism Vision With Ollama
I didn't find great documentation on how to actually set photoprism up to use photoprism-vision with Ollama. At first, I thought I'd simply need to add the vision container to my docker-compose.yaml and set a few environment variables:
services:
photoprism-vision:
image: photoprism/vision:latest
stop_grace_period: 5s
working_dir: "/app"
ports:
- "5000:5000"
environment:
OLLAMA_ENABLED: "true"
OLLAMA_HOST: "http://ollama.home:11434"
# See code: https://github.com/photoprism/photoprism-vision/blob/develop/service/ollama_processor.py#L15
#OLLAMA_NSFW_PROMPT: "Detect NSFW content."
#OLLAMA_LABELS_PROMPT: "Give me labels!"
#OLLAMA_CAPTION_PROMPT: "What can you see in the image?"
photoprism:
...
environment:
PHOTOPRISM_VISION_API: "true"
PHOTOPRISM_VISION_URI: "http://photoprism-vision:5000/api/v1/vision"
...
...
This didn't work for two reasons:
- The
visiondocker image I used was outdated (it has been updated now, didn't test it yet). - It tells PhotoPrism to use the new vision service for all model types, which I didn't want (just labels and caption for now, what Ollama supports, and I don't need an LLM to detect NSFW content that's hidden by default). This can probably be resolved by configuring in the
vison.yaml(see below) but I'm still confused about thePHOTOPRISM_VISION_APIflag.
After a bit of research I found the vision.yaml config file, which is apparently to be placed in storage/config/vision.yaml (the folder is mounted inside the container per default as /photoprism/storage). Finally, after some fiddling, my vision.yaml looks like this:
Models:
- Type: labels
Resolution: 224
Service:
Uri: http://host.docker.internal:5000/api/v1/vision/labels
FileScheme: data
RequestFormat: vision
ResponseFormat: vision
Tags:
- vision
- Type: nsfw
Name: Nsfw
Resolution: 224
Tags:
- serve
- Type: face
Name: FaceNet
Resolution: 160
Tags:
- serve
- Type: caption
Resolution: 224
Service:
Uri: http://host.docker.internal:5000/api/v1/vision/caption
FileScheme: data
RequestFormat: vision
ResponseFormat: vision
Tags:
- vision
Thresholds:
Confidence: 10
This will use the vision service running externally on the host for /labels and /caption requests, and the default models in PhotoPrism for NSFW and face detection.
I needed extra_hosts such that the photoprism container saw my locally running service (outside docker):
photoprism:
extra_hosts:
- "host.docker.internal:host-gateway"
One thing I didn't figure out yet is how to tell PhotoPrism which Ollama model to use, so I hacked it directly in the code like so:
def parse_model_info_from_request() -> tuple[str, str]:
- data = request.get_json() if request.is_json else request.args
- if data.get('model'):
- return data.get('model'), data.get('version', 'latest')
- raise ValueError("model name is required")
+ return "qwen2.5vl", "latest" # FIXME: How do I tell photoprism which model to use?
That's not great, and you can probably do this via the vision.yaml, but for now this works fine. By default the code looks for a :latest which may or may not exist locally in Ollama depending how you pulled the model in the first place.
Another thing that didn't work but could be resolved cleanly was the /labels requests to the vision API. PhotoPrism apparently sends 3 different versions (seem to be 3 different crops) of the same picture to this API endpoint. As was, the vision didn't support that, since it expected just a single image. I provided a fix via a pull request which was merged quickly.
Usage
So how is this used then? With the vision models activated as above, indexing automatically calls the /labels route on each picture, but not /caption. To generate captions, one can use the command line like so:
for year in {2017..2022}; do echo "generating captions for $year"; photoprism vision run --models caption year:$year --force; echo "done $year"; done
Instead of year:2017, one can use any of the other filters.
Models
First I ran Gemma3-4B via Ollama on my Mac Mini M4 Pro, which worked but was pretty slow, taking ~4s per request (/labels or /caption). Moving the service to my tower server which has an Ampere generation NVIDIA RTX A4000 GPU, that time could be reduced to ~3s. That's still a bit too slow to generate captions or labels for 80,000 pictures (all of this is done with a batch size of 1, so 160,000 total requests), so I looked for a better performing model. I also noticed that the Gemma3 model hallucinated quite a bit about cats... :-)
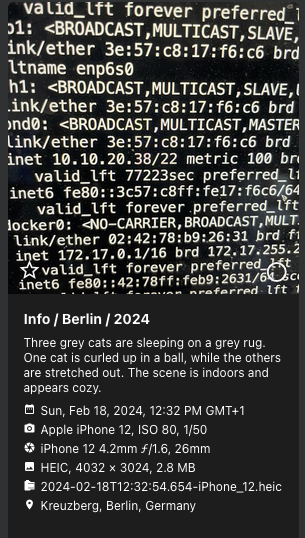
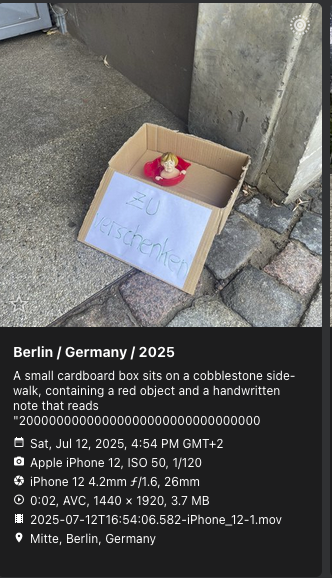
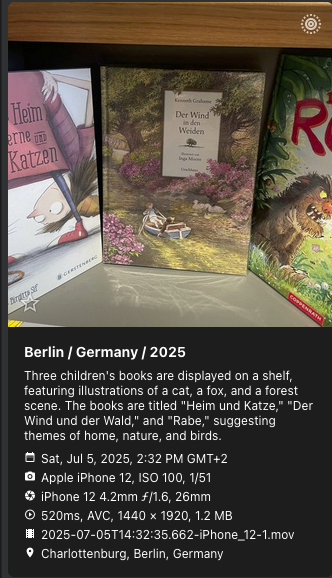
qwen2.5vl is the next highly ranked vision model for Ollama, so I naturally tried that. On my A4000 GPU requests with this model now take roughly 1.5s per request, which is acceptable. Captions also seem to be a bit more robust, although the model still hallucinates quite a bit on uncommon subjects:
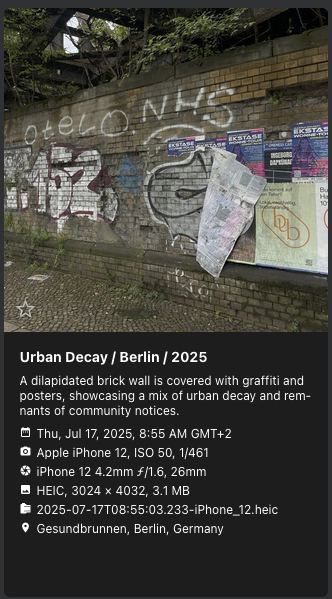
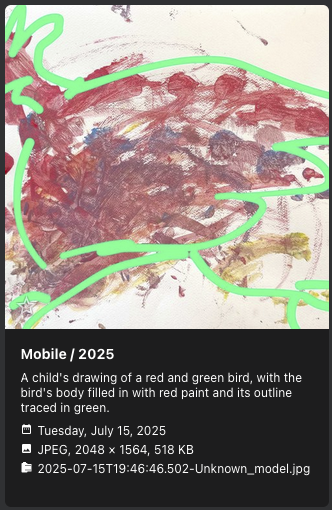
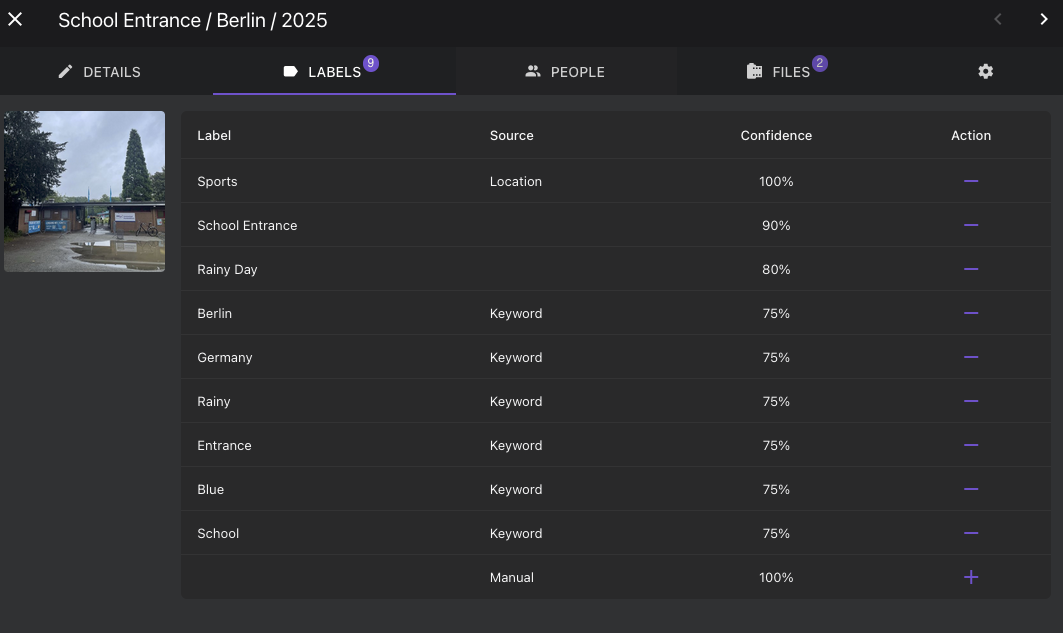
Conclusion
It's a great idea to have the machine learning models run in a separate service, that makes things much more flexible. Integrating with the powerful Ollama ecosystem and it's vision LLMs is actually really exciting, it was great to see that state-of-the-art vision models are actually helpful for managing my photo library.
A few things need to be cleaned up I suppose (from my end), like dockerizing (or rather use the official fixed docker image again) the service and getting rid of the model:tag hack.